306Measuring compact strings memory savings
Author: Dr Heinz M. KabutzDate: 2023-01-30Java Version: 17Sources on GitHubCategory: Performance
Abstract: JEP 254 replaced the char[] in our Strings with byte[]. How much memory does this save in our Strings? In this newsletter we show how we can determine this from a heap dump file.
Welcome to the 306th edition of The Java(tm) Specialists' Newsletter, sent from a cold and rainy Island of Crete. My run is beckoning me, whilst I carry on writing this newsletter for you. I'm hoping beyond reasonable doubt that the weather will clear up in the next few minutes, so that I can enjoy the crisp air, without getting drenched and/or struck by lightning.
javaspecialists.teachable.com: Please visit our new self-study course catalog to see how you can upskill your Java knowledge.
Measuring memory savings through compact strings
As you might know, I'm a super fan of IntelliJ IDEA. I even spoke at the recent Java Champions Conference on the topic of IntelliJ Super Productivity in 45 minutes. And at some point of my life, I might have made a dismissive remark about Netbeans. However, I have always maintained, and will continue to do so, that Netbeans, and especially Netbeans Platform, fulfills a vital role in the Java ecosystem. It has fans that are even more devoted than the IntelliJ devotees.
One of the beauties that Netbeans brings to the table is that it is more than just an IDE. It is a platform that we can build on and extend. In this newsletter we will do just that.
By now, we hopefully all know about JEP 254, where Java's strings were compacted from Java 9 onwards. Instead of using two bytes per character, Strings might be compacted to just a single byte, if all the characters fall in the LATIN1 character set. This can give us substantial space savings, depending on the length of our strings. Here is a graph that illustrates the cost savings vs length of string, assuming that they only use LATIN1 characters. Up until length=4, they use exactly the same. We reach 45% savings at length=165:
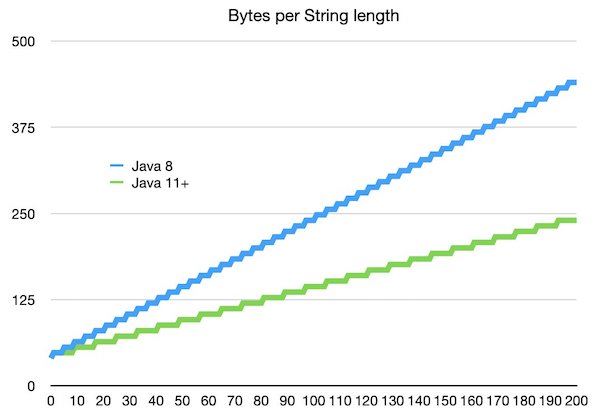
A question that was bugging me for a while was - how can I calculate the cost savings in Strings between Java 11+ and Java 8? Was there a way to analyze the heap and find all String instances? Fortunately I found an interesting talk by Ryan Cuprak that pointed me to an easy solution. Simply use the Netbeans profiler API for analyzing the heap. Since it is on Maven Central, we can add a dependency to our pom.xml file:
<dependency> <groupId>org.netbeans.modules</groupId> <artifactId>org-netbeans-lib-profiler</artifactId> <version>RELEASE160</version> </dependency>
Unfortunately the netbeans profiler api is not modularized with JPMS, thus we need to rely on automatic modules. Not ideal, but it works - for now. Here is my module-info.java file:
module eu.javaspecialists.tjsn.issue306 {
requires org.netbeans.lib.profiler.RELEASE160;
}
The code that analyses the heap dump looks like this. It's very simple - we read in the heap dump with Netbeans' HeapFactory. We then filter by the "java.lang.String" class and create StringData instances that contain the coder and the array length. Optionally we can print out all the Strings if we start with the -verbose parameter. At the end we see the total number of Strings and how much space we saved in Java 11 with JEP 254 vs Java 8.
package eu.javaspecialists.tjsn.issue306;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Locale;
import java.util.function.Predicate;
import java.util.stream.Stream;
import org.netbeans.lib.profiler.heap.HeapFactory;
import org.netbeans.lib.profiler.heap.Instance;
import org.netbeans.lib.profiler.heap.PrimitiveArrayInstance;
import static java.nio.charset.StandardCharsets.ISO_8859_1;
import static java.nio.charset.StandardCharsets.UTF_16LE;
public class HeapAnalysis {
private enum Coder {LATIN1, UTF16}
private record StringData(Coder coder, int length) {}
public static void main(String... args) throws IOException {
if (args.length < 1 || args.length > 2 ||
args.length > 1 && !args[0].equals("-verbose")) {
System.err.println("Usage: java HeapAnalysis " +
"[-verbose] heapdump");
System.exit(1);
}
var verbose = args.length == 2;
var filename = args[args.length - 1];
System.out.println("Inspecting heap file " + filename);
var heap = HeapFactory.createHeap(new File(filename));
var stringClass = heap.getJavaClassByName(
"java.lang.String");
var instances = stringClass.getInstancesIterator();
var stats = extractStringData(instances, verbose);
printStatistics(stats);
}
private static List<StringData> extractStringData(
Iterator<Instance> instances, boolean verbose) {
var result = new ArrayList<StringData>();
while (instances.hasNext()) {
Instance instance = instances.next();
Coder coder = getCoder(instance);
int length = getLength(instance, coder, verbose);
result.add(new StringData(coder, length));
}
return result;
}
private static Coder getCoder(Instance instance) {
Byte coder = (Byte) instance.getValueOfField("coder");
return switch (coder) {
case 0 -> Coder.LATIN1;
case 1 -> Coder.UTF16;
case null -> throw new IllegalStateException(
"Analysis for Java 11+ heap dumps only -"
+ " field coder not found in"
+ " java.lang.String");
default -> throw new IllegalStateException(
"Unknown coder: " + coder);
};
}
private static int getLength(Instance instance, Coder coder,
boolean verbose) {
var array = (PrimitiveArrayInstance)
instance.getValueOfField("value");
if (array == null)
throw new IllegalStateException(
"java.lang.String instances did not have a"
+ " value array field");
int length = array.getLength();
if (verbose) {
List<String> arrayValues = array.getValues();
byte[] bytes = new byte[length];
int i = 0;
for (String str : arrayValues)
bytes[i++] = Byte.parseByte(str);
System.out.println(switch (coder) {
case LATIN1 -> "LATIN1: "
+ new String(bytes, ISO_8859_1);
case UTF16 -> "UTF16: "
+ new String(bytes, UTF_16LE);
});
}
return length;
}
private static final Predicate<StringData> LATIN1_FILTER =
datum -> datum.coder() == Coder.LATIN1;
private static final Predicate<StringData> UTF16_FILTER =
datum -> datum.coder() == Coder.UTF16;
private static void printStatistics(List<StringData> data) {
long j8Memory = memoryUsed(data.stream(), 2);
long j11MemoryLatin1 =
memoryUsed(data.stream().filter(LATIN1_FILTER), 1);
long j11MemoryUTF16 =
memoryUsed(data.stream().filter(UTF16_FILTER), 2);
long j11Memory = j11MemoryLatin1 + j11MemoryUTF16;
var latin1Size = data.stream().filter(LATIN1_FILTER).count();
var utf16Size = data.stream().filter(UTF16_FILTER).count();
System.out.printf(Locale.US, """
Total number of String instances:
LATIN1 %,d
UTF16 %,d
Total %,d
""",
latin1Size, utf16Size, latin1Size + utf16Size);
System.out.printf(Locale.US, """
Java 8 memory used by String instances:
Total %,d bytes
""", j8Memory);
System.out.printf(Locale.US, """
Java 11+ memory used by String instances:
LATIN1 %,d bytes
UTF16 %,d bytes
Total %,d bytes
""", j11MemoryLatin1, j11MemoryUTF16, j11Memory);
System.out.printf(Locale.US, "Saving of %.2f%%%n", 100.0 *
(j8Memory - j11Memory) / j8Memory);
}
private static int memoryUsed(Stream<StringData> stats,
int bytesPerChar) {
return stats
.mapToInt(datum -> getStringSize(datum.length(),
bytesPerChar))
.sum();
}
private static int getStringSize(int length, int bytesPerChar) {
return 24 + 16 +
(int) (Math.ceil(length * bytesPerChar / 8.0) * 8);
}
}
Here is an example of our code running against a heap dump of IntelliJ IDEA:
Inspecting heap file idea.hprof
Total number of String instances:
LATIN1 2,656,321
UTF16 47,231
Total 2,703,552
Java 8 memory used by String instances:
Total 275,473,456 bytes
Java 11+ memory used by String instances:
LATIN1 192,371,520 bytes
UTF16 8,066,152 bytes
Total 200,437,672 bytes
Saving of 27.24%
And here is an analysis of my JavaSpecialists.eu Tomcat server:
Inspecting heap file javaspecialists.hprof
Total number of String instances:
LATIN1 165,865
UTF16 174
Total 166,039
Java 8 memory used by String instances:
Total 15,145,800 bytes
Java 11+ memory used by String instances:
LATIN1 11,210,944 bytes
UTF16 111,600 bytes
Total 11,322,544 bytes
Saving of 25.24%
I did not take into account that deduplication can share the same array instances. That would be a project for another rainy day.
I hope you enjoyed this newsletter. Stay safe and happy coding :-)
Heinz
Comments
We are always happy to receive comments from our readers. Feel free to send me a comment via email or discuss the newsletter in our JavaSpecialists Slack Channel (Get an invite here)
Related Articles
Browse the Newsletter Archive
About the Author

Java Champion, author of the Javaspecialists Newsletter, conference speaking regular... About Heinz
Superpack
 Our entire Java Specialists Training in one huge bundle
more...
Our entire Java Specialists Training in one huge bundle
more...
Free Java Book

Java Training
We deliver relevant courses, by top Java developers to produce more resourceful and efficient programmers within their organisations.